요즘 사무실에서 비는 시간이 좀 많이 있어서 책을 가져다두고 읽었다. 가볍게 읽으려고 읽었던 책을 가져가야지 했는데 지금 회사에서는 C#을 전혀 쓰지 않고 있으니 리마인드도 할 겸 읽게 되었다. 베타리딩을 포함해서 3번째 읽는데 그래도 또 배우는 게 많은 건 전에 열심히 안 읽어서 그런 걸까. 이번에는 읽고 기억하고 싶은 키워드라도 적어놔야지 싶어 표시해둔 부분을 여기에 옮겼다.
이 책은 어떤 방식으로 구조를 짜야 좋은 적응력을 가진 코드를 작성할 수 있는지 설명한다. 크게 세 부분으로 볼 수 있는데 가장 먼저 애자일 방법론과 적응형 코드를 작성하기 위한 배경적인 지식을 쌓는다. 그리고 SOLID 패턴에 대해 여러 예시를 들어 설명한 후, 마지막으로 실무에서 적용하는 예시로 마무리한다.
1부에서는 어떤 방식으로 작성하면 코드 의존성이 강해지는지, 어떤 계층적인 접근을 해야 유연한 구조를 구성할 수 있는지 풀어간다. 이런 흐름에서 왜 인터페이스를 도입해야 하고 디자인패턴이 어떻게 코드에 유연함을 더하는지 확인한다. 이런 구조의 코드를 어떻게 테스트하고 리팩토링하는 과정을 통해 개선하는 부분까지 다뤘다.
C#을 기준으로 설명하고 있어서 어셈블리를 어떻게 구성해야 한다거나 nuget을 구성하는 방법이라든가 하는 부분은 좀 거리감 있게 느낄 수도 있는데 요즘은 대다수 언어가 어떤 방식으로든 이런 부분을 지원하고 있으니 그렇게 맥락이 멀게 느껴지지 않았다.
의존성 관리(p. 66)에서 어떤 게 코드 스멜인지 알려주고 그 대안을 잘 설명하고 있다. C#에 매우 한정된 부분이긴 하지만 CLR의 어셈블리 해석 과정도 흥미로웠다.
여기서는 계층화를 점진적으로 진행하는 과정(p. 96)이 특히 좋았다. 인류 발달 과정 설명하듯 하나씩 짚어가며 어떤 이유에서 분리했는지 설명하고 있어서 최종 단계만 보면 막막할 수 있는 계층을 이해하는데 도움이 되었다.
2부에서는 SOLID 패턴을 하나씩 실질적인 예시와 함께 설명했다. 리스코프 치환 원칙을 설명하는 부분(p. 253~)이 재미있었다. 계약 규칙에서는 사전 조건과 사후 조건을 작성하는 방법과 불변성을 어떻게 유지해야 하는지 설명했다. System.Diagnostics.Contracts를 사용해서 각 조건을 기술하는 방식도 참 깔끔하다. 그리고 가변성 규칙에서 공변성과 반공변성을 짚고 넘어갔는데 제네릭이 어떤 식으로 동작하는지 이해하는데 많이 도움 됐다.
인터페이스 분리도 유익했는데 질의/명령을 인터페이스로 분리하는 부분도 좋았다. 의존성 주입은 이미 부지런히 쓰고 있었지만, 생명주기(p. 346)를 설명하는 부분은 다소 모호하게 생각했던 IDispose를 다시 살펴볼 수 있었고 이 인터페이스를 어떤 방식으로 생명주기 관리에 적용하는지 배울 수 있었다. 이 부분은 실무에서 좀 더 많은 사례를 접해보고 싶다.
예전에도 좋아서 추천 많이 했는데 또 읽어도 좋아서 추천하고 싶다. C#도 부지런히 해서 실무에서 다시 쓸 기회가 왔으면 좋겠다.
새로 옮긴 회사에서 열심히 레거시를 정리하고 있다. 기존 코드는 관리가 전혀 되지 않는 인하우스 프레임워크를 사용하고 있어서 전반적으로 구조를 개편하기 위해 고심하고 있다. 이 포스트는 Mark Seemann의 Service Locator is an Anti-Pattern를 번역한 글로 최근 읽었던 포스트 중 이 글을 레퍼런스로 하는 경우를 자주 봐서 번역하게 되었다.
아쉽게도 실제로는 그렇지 않습니다! 이 패턴은 안티 패턴으로 되도록 피해야 하는 방식입니다.
왜 안티 패턴인지 더 살펴보도록 합시다. 서비스 로케이터를 사용했을 때 나타나는 문제는 클래스의 의존성을 숨긴다는 점입니다. 다시 말해 컴파일 중에는 오류가 나타나지 않았지만 런타임에서는 오류가 발생할 여지가 있다는 이야기입니다. 이전에 작성한 코드와 호환이 되지 않는 방식으로 코드를 변경했다고 가정해봅시다. 어느 클래스가 어떤 클래스에 의존하고 있는지 명확하게 들어나지 않고 있는 상황에서는 그 변경이 어느 클래스에 영향을 미치는지 확인하기 어렵습니다. 그로 인해서 새로운 코드를 작성할 때마다 어디가 고장나는지 정확히 알 수 없어서 유지보수가 더 어려워질 수 밖에 없습니다.
OrderProcessor 예제
예제로 요즘 의존성 주입에서 가장 이슈라고 볼 수 있는 OrderProcessor를 살펴봅시다. 주문을 진행하기 위해서는 OrderProcessor에서 주문을 검증하고, 검증 결과에 문제가 없으면 배송을 처리합니다. 정적 서비스 로케이터의 예제는 다음과 같습니다.
public class OrderProcessor : IOrderProcessor
{
public void Process(Order order)
{
var validator = Locator.Resolve<IOrderValidator>();
if (validator.Validate(order))
{
var shipper = Locator.Resolve<IOrderShipper>();
shipper.Ship(order);
}
}
}
위 코드에서 new 오퍼레이터를 대체하려고 서비스 로케이터를 사용했습니다. Locator는 다음처럼 구현되어 있습니다.
public static class Locator
{
private readonly static Dictionary<Type, Func<object>>
services = new Dictionary<Type, Func<object>>();
public static void Register<T>(Func<T> resolver)
{
Locator.services[typeof(T)] = () => resolver();
}
public static T Resolve<T>()
{
return (T) Locator.services[typeof(T)]();
}
public static void Reset()
{
Locator.services.Clear();
}
}
이 Locator는 Register 메소드를 사용해서 설정할 수 있습니다. 물론 ‘실제’ 서비스 로케이터는 위 코드보다 훨씬 진보된 방식으로 구현되어 있지만 여기서는 이 간단한 예제 코드로도 충분히 문제를 확인할 수 있습니다.
이 로케이터는 확장이 가능하도록 유연하게 구현되었습니다. 또한 테스트 더블(Test Doubles)의 역할도 수행할 수 있어서 서비스를 테스트하는 것도 가능합니다.
이렇게 좋은 점이 많은데 어떤 부분이 문제가 될 수 있을까요?
API 사용 문제
단순하게 OrderProcessor 클래스를 사용한다고 가정해봅시다. 서드파티에서 제공한 어셈블리라면 우리가 코드를 직접 작성하지 않았기 때문에 Reflector를 사용해서 구현을 확인해야 할 것입니다.
비주얼 스튜디오의 인텔리센스는 다음 그림처럼 동작합니다.
자동완성을 보면 클래스가 기본 생성자를 포함하고 있습니다. 다시 말하면 이 클래스로 새 인스턴스를 생성한 다음에야 Process 메소드를 올바르게 실행할 수 있다는 뜻입니다.
var order = new Order();
var sut = new OrderProcessor();
sut.Process(order);
이 코드를 실행하면 예상하지 못한 KeyNotFoundException이 발생하는데 IOrderValidator가 Locator에 등록되지 않았기 때문입니다. 심지어 소스 코드에 접근할 수 없는 라이브러리나 패키지라면 어떤 부분으로 오류가 발생한 것인지 정확하게 판단하기 어렵게 됩니다.
소스 코드를 (또는 Reflector를 사용해서) 찬찬히 들여다 보거나, 문서를 참고해서 결국 IOrderValidator 인스턴스를 전혀 관련 없어 보이는 정적 클래스 Locator에 등록해야 한다는 사실을 아마도 발견할 수도 있을 겁니다.
유닛 테스트에서는 다음처럼 작성할 수 있습니다.
var validatorStub = new Mock<IOrderValidator>();
validatorStub.Setup(v => v.Validate(order)).Returns(false);
Locator.Register(() => validatorStub.Object);
Locator의 내부 저장소도 정적이라서 테스트를 작성하는 과정도 번거롭습니다. 매 유닛 테스트가 끝나는 순간마다 Reset 메소드를 실행해야 하기 때문인데요. 이 경우는 유닛 테스트의 경우에만 주로 해당되는 문제긴 합니다.
여기까지 살펴본 내용으로도 이 방식의 API는 긍정적인 개발 경험을 제공한다고 말하기엔 어렵다고 말할 수 있습니다.
관리 문제
사용자 관점에서도 서비스 로케이터를 사용하는 일이 문제가 가득하다는 것을 확인했지만 이 관점은 유지보수하는 개발자에게도 쉽게 영향을 미치게 됩니다.
public void Process(Order order)
{
var validator = Locator.Resolve<IOrderValidator>();
if (validator.Validate(order))
{
var collector = Locator.Resolve<IOrderCollector>();
collector.Collect(order);
var shipper = Locator.Resolve<IOrderShipper>();
shipper.Ship(order);
}
}
단순하게 본다면 매우 간단한 구현입니다. 그저 Locator.Resolve를 한 번 더 호출하고 IOrderCollector.Collect를 실행하는 코드로 끝납니다.
여기서 질문이 있습니다. 이 새로운 기능은 변경 전의 코드와 호환이 될까요?
놀랍게도 이 질문은 답변하기 어렵습니다. 일단 컴파일에서는 문제가 생기지 않지만 유닛 테스트는 실패하게 됩니다. 실제 프로그램에서도 문제가 발생했을까요? IOrderCollector 인터페이스가 다른 컴포넌트에서 사용되어서 이미 서비스 로케이터에 등록되어 있는 상황이라면 이 코드는 문제 없이 동작하게 됩니다. 그렇다면 정 반대의 상황도 가정해볼 수 있을 겁니다. 테스트는 통과하면서 실제로는 오류가 나는 경우도 완전 없다고 말하기는 어렵습니다.
결론적으로 서비스 로케이터를 사용하면 지금 변경한 코드가 문제를 만드는 변경인지 아닌지 판단하기 더욱 어려워지게 됩니다. 코드를 수정하거나 작성하기 위해서는 서비스 로케이터를 사용하는 어플리케이션 전체를 모두 이해해야만 합니다. 이 상황에서는 컴파일러도 도움을 줄 수 없겠죠.
변형: 구체적인 서비스 로케이터
이 문제를 해결할 방법은 없을까요?
문제를 해결할 방법을 찾아봅시다. 정적 클래스가 아닌 구체적인(구상, concreate) 클래스로 변경하면 가능할 것 같습니다.
public void Process(Order order)
{
var locator = new Locator();
var validator = locator.Resolve<IOrderValidator>();
if (validator.Validate(order))
{
var shipper = locator.Resolve<IOrderShipper>();
shipper.Ship(order);
}
}
하지만 여전히 설정이 필요해서 다음과 같은 정적 필드(services)를 활용하게 됩니다.
public class Locator
{
private readonly static Dictionary<Type, Func<object>>
services = new Dictionary<Type, Func<object>>();
public static void Register<T>(Func<T> resolver)
{
Locator.services[typeof(T)] = () => resolver();
}
public T Resolve<T>()
{
return (T) Locator.services[typeof(T)]();
}
public static void Reset()
{
Locator.services.Clear();
}
}
정리하면, 구체적인 클래스로 정의한 서비스 로케이터는 앞에서 작성한 정적 구현과 크게 구조적인 차이가 없습니다. 즉, 여전히 동일한 문제가 나타납니다.
변형: 추상 서비스 로케이터
다른 변형은 실제 의존성 주입이 동작하는 방식과 비슷합니다. 서비스 로케이터는 다음 IServiceLocator 인터페이스를 구현합니다.
public interface IServiceLocator
{
T Resolve<T>();
}
public class Locator : IServiceLocator
{
private readonly Dictionary<Type, Func<object>> services;
public Locator()
{
this.services = new Dictionary<Type, Func<object>>();
}
public void Register<T>(Func<T> resolver)
{
this.services[typeof(T)] = () => resolver();
}
public T Resolve<T>()
{
return (T) this.services[typeof(T)]();
}
}
이 변형은 결과적으로 서비스 로케이터를 필요로 하는 곳에 직접 주입하는 방식으로 동작합니다. **생성자 주입(Constructor Injection)**은 의존성 주입에서 좋은 방식이기 때문인데요. 이제 OrderProcessor를 다음처럼 변경해서 서비스 로케이터를 OrderProcessor 내에서 활용할 수 있게 됩니다.
public class OrderProcessor : IOrderProcessor
{
private readonly IServiceLocator locator;
public OrderProcessor(IServiceLocator locator)
{
if (locator == null)
{
throw new ArgumentNullException("locator");
}
this.locator = locator;
}
public void Process(Order order)
{
var valiator =
this.locator.Resolve<IOrderValidator>();
if (validator.Validate(order))
{
var shipper =
this.locator.Resolve<IOrderShipper>();
shipper.Ship(order);
}
}
}
이 정보가 유익한가요? 사실, 별 영양가가 없습니다. OrderProcessor가 ServiceLocator를 필요로 한다는 정보는 조금 더 알 수 있겠지만 실제로 이 서비스 로케이터에서 무슨 서비스를 꺼내 사용하고 있는지는 알 수 없습니다. 다음 코드는 컴파일이 가능하지만 코드를 실행하면 앞서 나타났던 KeyNotFoundException가 동일하게 발생하게 됩니다.
var order = new Order();
var locator = new Locator();
var sut = new OrderProcessor(locator);
sut.Process(order);
유지보수를 하는 개발자 입장에서도 향상된 부분이 딱히 없습니다. 다른 서비스에 의존적인 코드를 추가하더라도 문제가 발생하는지 안하는지 확답해서 말하기 여전히 어렵습니다.
정리
서비스 로케이터 문제는 특정 서비스 로케이터 구현을 사용한다고 해서 발생 유무가 달라지는 문제가 아닙니다. 이 패턴을 사용하면 언제든 문제가 나타나는, 진정한 안티-패턴입니다. (물론 특정 구현에 더 문제가 있는 경우는 얼마든지 있습니다.) 이 패턴은 API를 소비하는 모든 사용자에게 끔찍한 개발 경험을 제공합니다. 유지보수를 하는 개발자 입장에서는 변경 하나 하나를 만들 때마다 두뇌를 풀가동해서 변경이 미치는 모든 영향을 파악해야 하므로 더욱 고통스러워질 것입니다.
생성자 주입을 사용한다면 컴파일러는 코드를 소비하는 사람과 생산하는 사람 모두에게 도움이 됩니다. 서비스 로케이터에 의존하는 API라면 이런 도움을 전혀 받을 수 없습니다.
지난 21일 Weird Developer Melbourne 밋업이 있었다. 3회차인 이번 밋업은 라이트닝 토크 형식으로 진행되었고 그 중 한 꼭지를 맡아 C# 초보가 C# 패키지를 만드는 방법 주제로 발표를 했다.
C# 스터디에 참여한 이후에 윈도 환경에서 작업할 일이 있으면 C#으로 코드를 작성해서 사용하기 시작했다. 하지만 업무에서 사용하는 기능은 한정적인데다 의도적으로 관심을 갖고 꾸준히 해야 실력이 느는데 코드는 커져가고, 배운 밑천은 짧고, 유연하고도 강력한 코드를 만들고 싶다는 생각을 계속 하고 있었지만 실천에 옮기질 못하고 있었다.
얼마 전 저스틴님과 함께 바베큐를 하면서 이 얘기를 했었는데 “고민하지 않고 뭐든 만드는 것이 더 중요하다”는 조언을 해주셨다. 말씀을 듣고 그냥 하면 되는걸 또 너무 망설이기만 했구나 생각이 들어서 실천에 옮겼다. 특별하게 기술적으로 뛰어난 라이브러리를 만들거나 한 것은 아니지만 생각만 하고 앉아있다가 행동으로 옮기는 일을 시작한 계기와 경험이 좋아서 발표로 준비하게 되었다.
현재 중간 규모의 프로젝트를 개발자 3명이서 6개월 넘게 진행하고 있다. 구체적인 구현에서 인터페이스를 분리하자는 결론에 이르렀다. 가장 먼저 인터페이스를 별도의 파일로 보관하기로 했다.
추가적으로 데이터를 더 분리하기 위해서 인터페이스 .CS 파일과 헬프 클래스 .CS 파일(이 인터페이스를 사용하는 퍼블릭 클래스나 enum 등)을 담은 프로젝트(CSPROJ)를 만들었다. 그리고 팩토리 패턴이나 구체적인 인터페이스 구현, 다른 “워커” 클래스 등을 별도의 프로젝트(CSPROJ)로 만들었다.
어떤 클래스든 인터페이스를 구현하는 개체를 생성하려면 그 자체만으로 구현하지 않고 인터페이스와 퍼블릭 클래스를 포함하는 첫 번째 프로젝트로 분리한 다음에 해당 프로젝트를 포함하는 방식으로 작성했다.
이 해결책은 큰 단점이 있다. 어셈블리 수가 2배로 늘게 된다는 점인데 모든 “일반” 프로젝트가 하나의 인터페이스 프로젝트와 하나의 구현 프로젝트를 포함하게 되기 때문이다.
당신의 추천은 무엇인가? 각각 프로젝트 자체에 인터페이스를 보관하는 것보다 인터페이스 만을 위한 별도의 프로젝트 하나를 갖는 것이 좋은 생각인가?
**독자적 인터페이스 (Standalone interfaces)**는 프로젝트 나머지와 소통할 필요 없이 사용할 수 있도록 제공하는 목적에서 작성한다. 이런 인터페이스는 단일 항목으로 “인터페이스 어셈블리(interface assembly)”에 넣게 되고 프로젝트 내 모든 어셈블리가 참조할 것이다. ILogger, IFileSystem, IServiceLocator가 전형적인 예시다.
**클래스 결합 인터페이스 (Class coupled interfaces)**는 오직 프로젝트 내의 클래스와 사용하는 맥락에서만 이해가 되는 경우다. 이 인터페이스는 의존성을 갖는 클래스와 동일한 어셈블리에 포함한다.
예를 들어보자. 도메인 모델이 Banana 클래스를 갖고 있다고 가정한다. 바나나를 IBananaRepository 인터페이스를 통해서 얻을 수 있다면 이 인터페이스는 바나나와 밀접하게 결합된 상황이다. 이 경우에는 바나나에 대해 알지 못하고서는 이 인터페이스를 구현을 한다거나 이 인터페이스를 사용하는 일이 불가능하다. 그러므로 이 인터페이스는 바나나 어셈블리와 함께 위치하는 것이 논리적이다.
앞 예제는 기술적인 결합이지만 논리적으로 결합하는 경우도 있다. 예를 들면, IFecesThrowingTarget 인터페이스는 Monkey 클래스에 기술적인 연결 고리로 선언되어 있지 않더라도 Monkey 클래스와 함께 사용하는 경우에만 유의미할 수 있다.
내 답변은 개념에 의존적이지 않으며 클래스가 약간 결합하는 정도는 괜찮다고 생각한다. 모든 구현을 인터페이스 뒤에 숨기는 일을 실수일 것이다. 의존성을 주입하거나 팩토리를 통해 인스턴스를 생성하지 않고 그냥 클래스를 “new 키워드로 생성”하는 것도 괜찮을 수도 있다.
msdn 블로그에 게시된 New Features in C# 6포스트를 요약했다. C# 6는 VS 2015 프리뷰와 함께 제공된 버전으로 여러가지 문법 특징이 추가되었다. 이 포스트는 요약이라 내용이 좀 부실할 수 있는데 상세한 내용은 위 포스트를 참고하자.
표현식
nameof
새로운 형태의 문자열로 프로그램 요소의 이름을 간혹 알아내야 할 상황을 마주하는데 그때 사용할 수 있는 표현식이다. 점 표기법(dot notation)을 사용한 경우 가장 마지막 식별자를 반환한다.
if (x == null) throw new ArgumentNullException(nameof(x));
WriteLine(nameof(person.Address.ZipCode)); // prints "ZipCode"
person이 스코프 내에서 타입이 아닌 변수라면 두번째 코드는 허용되지 않는다.
문자열 인터폴레이션
번거로웠던 String.Format()을 간편하게 작성할 수 있다.
var s = String.Format("{0} is {1} year{{s}} old", p.Name, p.Age);
s = "\{p.Name} is \{p.Age} year{s} old";
s = "\{p.Name,20} is \{p.Age:D3} year{s} old"; // 형식 지정
s = "\{p.Name,20} is \{p.Age:D3} year{(p.Age == 1 ? "" : "s")} old"; // 표현식도 쓸 수 있음
Note. 프리뷰 이후 문법이 변경되었다. s = $"{p.Name,20} is {p.Age:D3} year{{s}} old";
Null 조건부 연산자
체이닝 등 호출이 연속적으로 이뤄지는 상황에서 null 확인을 더 쉽게 만드는 연산자다.
int? length = customers?.Length; // customers가 null이면 null 반환
Customer first = customers?[0]; // customers가 null이면 null 반환
// null 병합 연산자인 ??와 함께 사용. customers가 null 일 때, 값은 0
int length = customers?Length ?? 0;
// 뒤에 따라오는 멤버 접근, 엘리먼트 접근 등은 customers가 null이 아닐 때만 호출
int? first = customers?[0].Orders.Count();
// 위와 동일한 표현
int? first = (customers != null) ? customers[0].Orders.Count() : null;
int? first = customers?[0].Orders?.Count(); // 연속으로 사용 가능
다만 ?을 사용한 직후에는 문법적으로 모호함이 있어서 바로 호출을 할 수 없다. 그래서 바로 대리자를 호출할 경우 다음과 같이 작성해야 한다.
Resource res = null;
try
{
res = await Resource.OpenAsync( ... ); // 원래 되던 부분
}
catch(ResourceException e)
{
await Resource.LogAsync(res, e); // 이제 가능한 부분
}
finally
{
if (res != null) await res.ColseAsync(); // 여기서도 가능
}
맴버 선언
자동 프로퍼티 이니셜라이저
필드에 이니셜라이져 하는 것과 비슷하다. 이 방법으로 이니셜라이징 하면 setter를 거치지 않고 내부 형식 바로 저장이 된다.
public class Customer
{
public string First { get; set; } = "Jane";
public string Last { get; set; } = "Doe";
}
Getter only 자동 프로퍼티
setter 없이 자동 프로퍼티를 사용하는게 허용된다. 이 방식은 readonly로 암묵적인 선언이 된다.
public class Customer
{
public string First { get; } = "Jane";
public string Last { get; } = "Doe";
}
위와 같이 초기화 하지 않는 경우에는 다음과 같이 타입 생성자에서 선언하면 값이 내부 형식에 바로 저장된다.
public class Customer
{
public string Name { get; };
public Customer(string first, string last)
{
Name = first + " " + last;
}
}
이 문법은 표현 타입을 더 간소하게 만든다. 하지만 변형 가능한 타입과 불변 타입의 차이가 없어진다. 변형 가능한 클래스도 상관이 없다면 자동 프로퍼티를 기본으로 사용하는 것도 좋다. 여기다 getter only 자동 프로퍼티는 변형 가능한 타입과 불변 타입을 더 비슷하게 만든다.
표현-본문 함수 멤버
표현-본문 함수 멤버는 메소드와 프로퍼티, 다른 종류의 함수 멤버들의 본문을 블럭이 아닌 람다처럼 표현식을 바로 쓸 수 있도록 지원한다. 실제로 람다처럼 람다 화살표로 작성한다. 블럭 본문에 단일 반환값을 가진 형태와 동일하다.
public Point Move(int dx, int dy) => new Point(x + dx, y + dy);
public static Complex operator +(Complex a, Complex b) => a.Add(b);
public static implicit operator string(Person p) => $"{p.First} {p.Last}";
void를 반환하는 메소드, Task를 반환하는 비동기 메소드에서도 동일하게 사용할 수 있지만, 이 경우에는 람다에서와 같이 꼭 문 표현식(statement expression)이 사용해야 한다.
public void Print() => Console.WriteLine(First + " " + Last);
프로퍼티와 인덱서도 다음과 같이 쓸 수 있다. get 키워드가 없는 대신 표현식 본문 문법에 따라 암묵적으로 사용된다.
public string Name => First + " " + Last;
public Customer this[long id] => store.LookupCustomer(id);
파라미터 없는 구조체 생성자
파라미터 없는 구조체 생성자가 허용되었다. 다음 구조체에서 new Person()은 선언된 생성자에 따라 기본값을 제공한다. default(Person)로 기본값을 사용하거나 new Person[...] 형태로 배열을 사용하면 해당 생성자는 실행되지 않는다. 명시적으로 구조체 타입과 함께 new 키워드를 사용했을 때만 해당된다.
struct Person
{
public string Name { get; }
public int Age { get; }
public person(string name, int age) { Name = name; Age = age; }
public Person() : this("Jane Doe", 37){ }
}
임포트
using static
using 으로 정적 멤버 타입을 스코프에서 직접 사용할 수 있다. 프리뷰에서는 정적 클래스의 멤버만 불러올 수 있다.
using System.Console;
using System.Math;
class Program
{
static void Main()
{
WriteLine(Sqrt(3*3 + 4*4));
}
}
Note. 다음과 같이 디자인이 변경되었다.
using에서 using static으로 변경
구조체나 enum과 같은 멤버의 비정적 타입을 임포트 할 수 있음
VB 모듈의 멤버나 F#의 최상위 함수를 임포트 할 수 있음
최상위 스코프에서 확장 메소드는 임포트 할 수 없음. 확장을 해온 원 클래스는 불러오지 않고 확장 메소드만 불러오면 안되기 때문.
이 글을 뒤늦게 확인하고 C#6의 문법적인 변경점을 살펴봤다. (아직 기본적인 문법도 잘 모르긴 하지만.) C# 개발은 얼마 해보지 못했는데 문자열 인터폴레이션만 봐도 편리한 기능들이 많이 나오는구나 느낄 수 있었다. 이번 달 아니면 다음 달 내로 베타가 시작될 것 같은데 기대된다.
최근 회사 프로젝트에서 C# 어플리케이션을 obfuscate 하면서 알게 된 부분들을 정리한 포스트.
내 (얕은) 지식으로는 컴파일 언어는 “컴파일러를 통해 바이너리로 치환되서 컴파일된 결과물만 가지고 소스를 복구할 수 없다”고 알고 있었는데 현대 언어에서는 그게 그렇게 단순한 부분이 아닌 것 같다. C# 프로그램은 dll이든 exe든 디컴파일러를 통해 내부 구조를 볼 수 있다. 심지어 그런 디컴파일러가 불법적으로 암암리에 유포된다거나 하는 것이 아니라 무료로 공개되어 있기도 하고 다들 많이 사용하는 모양이다. (예를 들면, Jetbrain의 dotpeek.)
컴파일 언어인데 어떻게 가능하지
C# 왕초보라 정확한 설명인지는 잘 모르겠지만 이것저것 찾아서 읽어본 글에 따르면,
C#은 Common Language Runtime(CLR) 위에서 돌아가는 언어
CLR은 MS에서 Common Language Infrastructure(CLI)를 구현한 구현체
CLI 규격에 의해 C#도 메타데이터를 포함
C#의 경우 이 메타데이터가 가지는 장점으로 쉽게 reflection 가능한 구조로 되어 있고 이를 통해 어셈블리의 타입이나 멤버, 메소드, 심지어는 내부 로직까지도 들여다볼 수 있다고 한다.
좋은 일에 쓴다면 엄청난 효율을 만드는 장점이지만 내부 로직이 공개될 위험이 있다. 그래서 디컴파일을 방지할 수 있는가에 대한 답변을 SO에서 찾아봤는데 대부분 답변이 둘로 수렴했다. 하나는 obfuscate 난독화를 하는 것이고, 다른 하나는 PaaS로 서비스하라는 얘기였다. 현재 프로젝트는 장기적으로 PaaS로 가겠지만 일단은 전자의 방식을 사용하기로 결정했다.
C# 난독화
Obfuscation은 코드를 읽기 어렵게 만들어서 내부 로직을 쉽게 들여다볼 수 없게 만드는 과정이다. 메소드, 변수 등을 a, b, c 등으로 수정해서 무슨 로직으로 동작하는지 알아보기 어렵게 만드는 것이다. 목적은 다르지만 결과물로 보면 JavaScript에서 js minify 한 것과 비슷하다.
Obfuscate하는 도구는 시중에 엄청 많이 나와 있는데 Visual Studio 2012를 설치하면 포함되어 있는 Dotfuscator를 사용했다. Dotfuscator의 사용 방법은 파일 추가 > 결과물 위치 지정 > 실행, 3단계로 아주 단순하다.
다만 Dotfuscator를 하게 되면 모든 클래스, 메소드 등 대부분의 명칭이 a, b, c 와 같이 변하기 때문에 문제가 되는 부분이 있을 수 있다. 가령 JSON을 사용하는 경우라면 Serialize 될 때 해당 멤버변수명을 그대로 사용해야 한다. 그런 경우 다음과 같이 attribute로 예외를 지정해주면 된다.
class PolicyContainer
{
[Obfuscation(Feature = "renaming", Exclude = true)]
public IList<POLICY> Policys;
...
ConfigurationManager.appSettings를 Serialize해서 다른 곳에 전송하는 것은 어떨까 하는 아이디어를 듣고 코드를 작성해 Json.NET을 사용해서 SerializeObject를 했다. appSettings는 NameValueCollection 클래스인데 Dictionary와 같이 serialize 될 것이라 예상했지만 결과는 키값만 배열로 반환했다.
var col = new System.Collections.Specialized.NameValueCollection(){
{"a", "Hello"}, {"a", "World"}
};
Console.WriteLine(JsonConvert.serializeObject(col));
// return "[\"a\"]"
NameValueCollection은 하나의 키에 여러개의 값을 가질 수 있는 컬렉션이기 때문에 Dictionary와는 다른 형태로 serialize되도록 NameObjectCollectionBase에서 구현되어 있는 것으로 보인다.
C#을 쓸 일이 종종 있는데 아직 초보 수준이라서 모르는 문법이 많다. 코드를 읽다가 메서드 선언 앞에 나온 물결 문자를 보게 되었는데 관련된 내용을 찾아봤다. 다음 내용은 함수명 앞에 오는 물결 표시는 무슨 의미인가요?에 나온 답변이다.
C#에서 메소드 선언 앞에 나오는 ~(물결 문자, 틸드)는 소멸자다.
소멸자는 자동으로 동작하며 명시적으로 실행할 수 없다.
소멸자는 오버로드가 불가능하다. 그러므로 클래스는 최대 하나의 소멸자를 가질 수 있다.
소멸자는 상속되지 않는다. 그러므로 클래스는 하나 이외의 소멸자를 가지지 않게 되고 그 소멸자는 해당 클래스에서 선언이 되어야만 한다.
소멸자는 구조체에서는 사용할 수 없다. 클래스에서만 사용 가능하며 어떤 코드에서도 더 이상 인스턴스를 사용하지 못하게 될 때 소멸될 자격이 주어진다.
인스턴스의 소멸자는 인스턴스가 소멸될 자격만 된다면 언제든 실행이 된다.
인스턴스가 소멸될 때 소멸자는 상속 체인을 따라 자식-부모 순으로 순차적으로 호출된다.
Finalize
C#에서 Finalize 메소드는 표준 C++ 소멸자처럼 동작한다. C#에서는 Finalize라고 메소드에 이름 붙이는 것 대신 C++의 소멸자 문법처럼 물결 표시를 메소드명 앞에 붙인다.
Dispose
객체를 정리하기 위해 명시적으로 호출이 가능한 메소드 Close() 또는 Dispose()를 제공하는 것이 바람직하다. 소멸자는 GC에 의해 호출되기 때문이다.
IDisposable 인터페이스는 클래스가 가지고 있는 자원이 정리되어야 한다는 것을 알려주며 실제로 정리될 수 있는 방법을 제공해준다. 만약 소멸자를 직접 구현해야 한다면 그 클래스의 정리(Dispose) 메소드는 GC.SuppressFinalize() 메소드를 꼭 실행해 인스턴스를 강제적으로 제거해야 한다.
What to use?
명시적으로 소멸자를 호출하는 것은 허용되지 않는다. 소멸자는 가비지 컬렉터에 의해 호출된다. 만약 file을 다루는 것과 같이 처리 비용이 비싸 관리되지 않는 자원들을 다루게 되면 가능한한 빠르게 닫고 정리하기를 원할 것이다. 이런 경우에는 IDisposable 인터페이스를 구현해야 한다.
class First
{
~First()
{
System.Diagnostics.Trace.WriteLine("First's destructor is called.");
}
}
class Second : First
{
~Second()
{
System.Diagnostics.Trace.WriteLine("Second's destructor is called.");
}
}
class Third : Second
{
~Third()
{
System.Diagnostics.Trace.WriteLine("Third's destructor is called.");
}
}
class TestDestructors
{
static void Main()
{
Third t = new Third();
}
}
/* Output (to VS Output Window):
Third's destructor is called.
Second's destructor is called.
First's destructor is called.
*/
OWIN은 Open Web Interface for .NET의 약어로 요즘 MS 진영에서 핫한(?) 오픈소스 프로젝트다. 다음은 OWIN 공식 사이트에 나와 있는 프로젝트의 목표.
The goal of the OWIN interface is to decouple server and application, encourage the development of simple modules for .NET web development, and, by being an open standard, stimulate the open source ecosystem of .NET web development tools.
MS에서 제공하는 ASP.NET MVC framework는 System.Web에, 특히 HttpContext에 깊은 의존성이 있어서 IIS 이외에는 구동이 불가능하다. 하지만 OWIN 구현을 통해 웹서버와 어플리케이션의 의존성이 분리1되어 IIS 이외의 웹서버에서도 C#으로 작성된 웹 어플리케이션을 구동할 수 있게 되었다.2 OWIN은 인스턴스로 처리하기 간편한 구조라 횡적으로 확장이 쉬운데다 서버의 유연성까지 보장하고 있다. OWIN을 이용해 개발한다면 ASP.NET MVC을 기반으로 작업할 수 없지만3 Nancy나 Simple.Web 등 다양한 프레임워크/라이브러리를 활용할 수 있다.
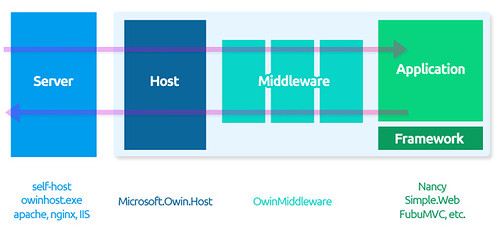
OWIN의 구조
OWIN 명세에서는 각각 서버, 웹프레임워크, 웹 어플리케이션, 미들웨어, 호스트로 정의했다. 발번역(…)하면 다음과 같다.
서버: HTTP 서버로 클라이언트와 직접 소통. 요청을 처리하는데 OWIN 문맥을 사용. 서버는 OWIN 문맥을 이해할 수 있도록 돕는 어뎁터 레이어가 필요.
웹 프레임워크: 요청을 처리하는데 사용하는 어플리케이션을 OWIN에서 원활하게 구동할 수 있도록 돕는 독립적 컴포넌트. OWIN 문맥을 이해할 수 있는 어뎁터 레이어 필요.
웹 어플리케이션: 웹프레임워크 위에서 개발 가능하며, OWIN 호환 서버에서 구동이 가능한 특정 어플리케이션.
미들웨어: 서버와 어플리케이션 사이의 파이프라인을 통과해 구동되는 컴포넌트로 특정의 목적에 따라 응답과 요청을 점검, 라우팅 또는 수정할 수 있음.
호스트: 서버 내에서 어플리케이션을 실행하기 위해 우선적으로 응답하는 어플리케이션 실행부. 특정 서버는 호스트의 역할도 수행함.
OWIN의 전체적인 흐름은 다음과 같다.
서버를 통해 요청이 들어오면 호스트는 Startup 클래스에 정렬된 파이프라인을 따라 미들웨어를 실행한 후 어플리케이션을 실행한다. 어플리케이션 실행 후 응답 또한 미들웨어를 거쳐 빠져나간다. 미들웨어는 Task를 이용해 다음 파이프라인으로 컨텍스트를 넘겨준다. 각각의 미들웨어는 앞서의 정의처럼 응답과 요청을 조작할 수 있다.
OWIN 명세에서는 AppFunc라고 불리는 어플리케이션 대리자(delegate)를 통해 환경을 주고 받는다. 명세에서는 다음과 같이 환경과 Task로 구성되어 있다.
환경은 크게 요청, 응답, 기타 데이터로 구분되는데 자세한 내용은 OWIN 스펙에서 찾아볼 수 있다. MS에서는 OWIN 명세를 기반으로 Katana라는 이름으로 프로젝트를 진행하고 있는데(Microsoft.Owin) 여기에서는 IOwinContext 인터페이스를 활용할 수 있다. 이 포스트의 예제에서도 IOwinContext를 사용하고 있다.
맛보기 코드
OWIN 어플리케이션
이 포스트에서는 누구나 따라해볼 수 있도록 Mono 환경을 기준으로 작성했다. IDE로는 Xamarin Studio를 사용했다.
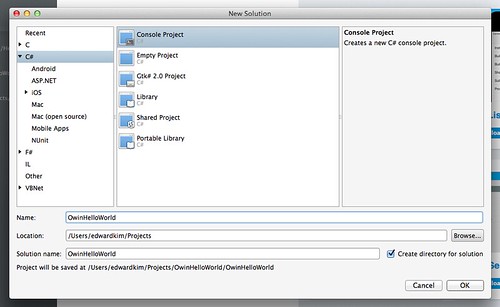
Xamarin Studio을 실행해 새 솔루션을 생성한다. Console에서 self-host로 구동하는 예제이므로 Console Project를 선택한다. (Visual Studio를 이용하는 예제에서는 Web Empty Project를 사용해도 된다.4)
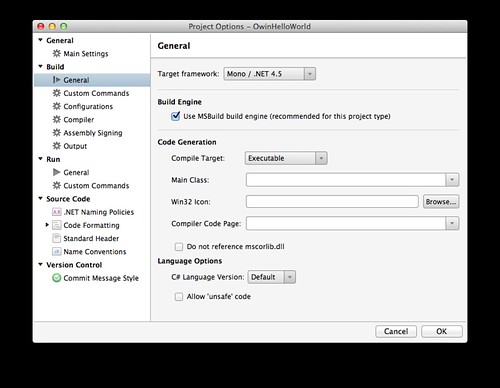
먼저 최신 패키지 설치를 위해 target framework를 Mono / .NET 4.5로 변경해야 한다. 해당 솔루션의 옵션에서 Build > General에서 변경할 수 있다.
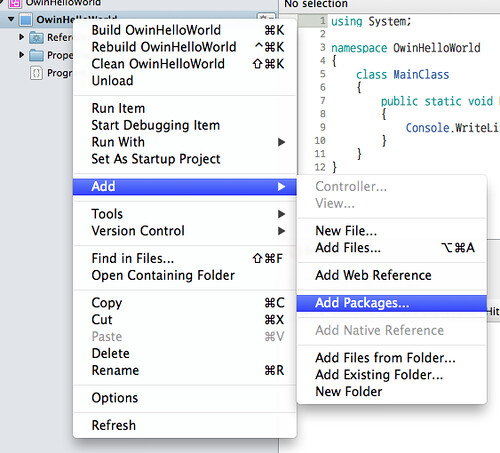
솔루션에 패키지를 추가한다. 솔루션에 오른쪽 클릭해서 Add > Add Packages... 를 클릭한다.
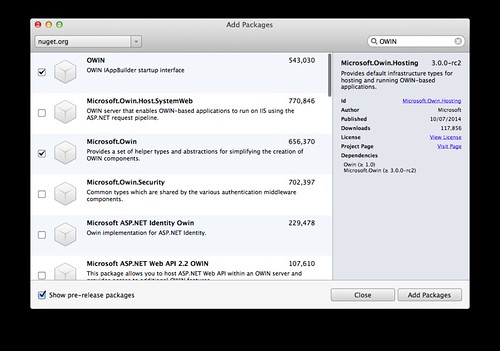
Show pre-release packages를 체크하고 Owin을 검색한다. 검색 결과에서 OWIN, Microsoft.Owin, Microsoft.Owin.Hosting, Microsoft.Owin.Host.HttpListener를 체크하고 Add Packages 버튼을 누른다.
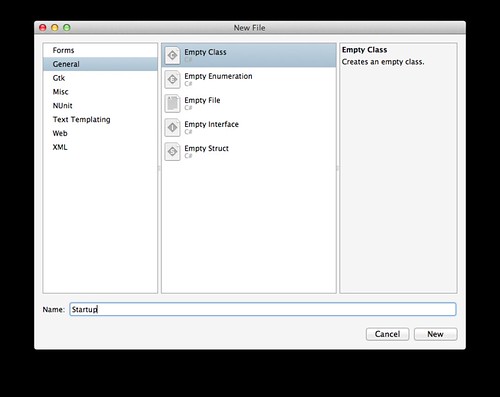
using System;
using Owin;
using Microsoft.Owin;
[assembly: OwinStartup(typeof(OwinHelloWorld.Startup))]
namespace OwinHelloWorld
{
public class Startup
{
public void Configuration(IAppBuilder app)
{
app.Run (context => {
context.Response.ContentType = "text/html";
return context.Response.WriteAsync("<h1>It Works</h1>");
});
}
}
}
이 Startup 클래스의 Configuration(IappBuilder app)메소드를 통해서 어떤 미들웨어에 어떤 순서로 접근하며(app.Use()) 최종적으로 어떤 어플리케이션이 실행되는지(app.Run()) 작성하게 된다.
[assembly: OwinStartup(typeof(OwinHelloWorld.Startup))] 부분은 이 Owin 코드가 컨테이너 형태로 실행될 때 엔트리 포인트를 지정해주는 부분이다. (이외에도 appsettings에 추가해주거나 owinhost.exe를 실행할 때 미리 선언한 identifier를 사용하는 방법이 있다.)
이제 이 인터페이스를 실질적으로 접근 가능하게 만들어줄 콘솔 어플리케이션을 작성한다. Program.cs를 열어 다음의 코드를 입력한다.
using System;
using Microsoft.Owin.Hosting;
namespace OwinHelloWorld
{
class MainClass
{
public static void Main (string[] args)
{
var url = "http://localhost:9000";
using (WebApp.Start<Startup> (url)) {
Console.WriteLine (url);
Console.WriteLine ("Press enter to quit.");
Console.ReadLine ();
}
}
}
}
Microsoft.Owin.Hosting.WebApp으로 Startup 클래스를 구동한다. 이 과정에서 내부적으로 Microsoft.Owin.Host.HttpListener를 사용한다.
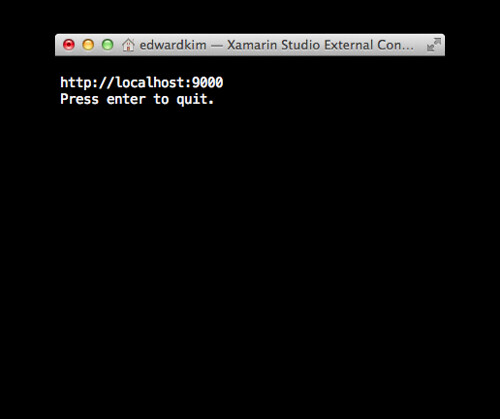
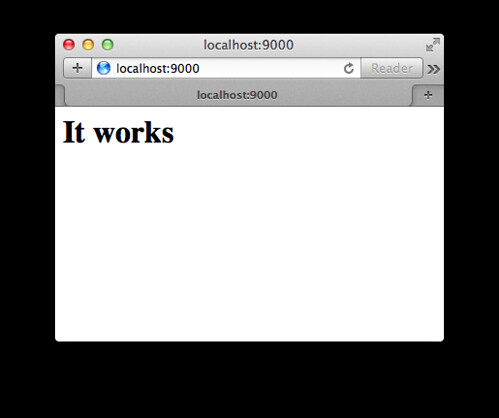
이제 프로젝트를 빌드하고 실행하면 다음과 같은 콘솔 화면이 나타난다.
그리고 해당 주소를 브라우저에서 열면 페이지를 확인할 수 있다.
미들웨어 Middleware
미들웨어 간의 소통은 앞에서 말한 appFunc를 사용해 환경과 컨텍스트를 넘겨주는데 여기 예제에서는 Katana에서 제공하는 OwinMiddleware 클래스와 IOwinContext 인터페이스를 활용해 미들웨어를 작성할 것이다.
다음은 MyFirstMiddleware.cs의 코드다.
using System;
using System.Threading.Tasks;
using Owin;
using Microsoft.Owin;
namespace HelloWorldOwin
{
public class MyFirstMiddleware : OwinMiddleware
{
public MyFirstMiddleware (OwinMiddleware next) : base(next)
{
}
public override async Task Invoke(IOwinContext context){
context.Response.Write ("<!doctype html><html><body>");
await Next.Invoke (context);
context.Response.Write ("</body></html>");
}
}
}
OwinMiddleware 클래스를 상속받는 MyFirstMiddleware로 Invoke(IOwinContext) 메소드를 사용해 해당 미들웨어에서 데이터를 핸들링 하거나 응답/요청을 변경하는 등의 코드를 작성할 수 있다.
다음은 MySecondMiddleware.cs의 코드다.
using System;
using System.Threading.Tasks;
using Owin;
using Microsoft.Owin;
namespace HelloWorldOwin
{
public class MySecondMiddleware : OwinMiddleware
{
public MySecondMiddleware (OwinMiddleware next) : base(next)
{
}
public override async Task Invoke(IOwinContext context){
context.Response.Write ("<header><h1>It works</h1></header>");
await Next.Invoke (context);
context.Response.Write ("<footer><a href=\"http://localhost:9000\">http://localhost:9000</a></footer>");
}
}
}
파이프라인의 흐름을 보여주기 위해서 그냥 예시 코드를 넣은 두번째 미들웨어다. 마지막으로 Startup.cs로 돌아가서 해당 미들웨어를 파이프라인으로 집어 넣는다.
using System;
using Owin;
using Microsoft.Owin;
[assembly: OwinStartup(typeof(HelloWorldOwin.Startup))]
namespace HelloWorldOwin
{
public class Startup
{
public void Configuration(IAppBuilder app)
{
app.Use (typeof(HelloWorldOwin.MyFirstMiddleware));
app.Use (typeof(HelloWorldOwin.MySecondMiddleware));
app.Run (context => {
context.Response.ContentType = "text/html";
return context.Response.WriteAsync("<p>Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p>");
});
}
}
}
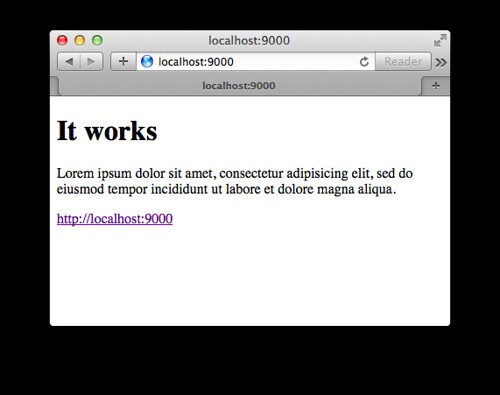
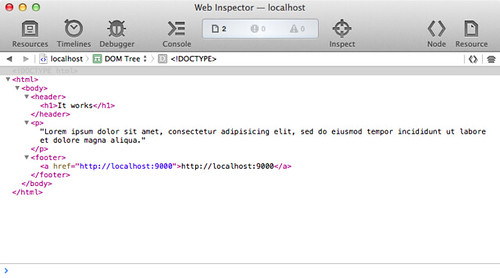
app.Use()로 각각의 미들웨어를 연결했다. 앞서 예제와 동일하게 구동해보면 다음 결과를 볼 수 있다.
특별한 예제가 딱히 떠오르지 않아서 그냥 html 코드를 넣었는데 GitHub이나 nuget 리포지터리에 OAuth Autentication 같은 멋진 미들웨어가 많이 있어 위와 같이 간편하게 추가만 하면 사용이 가능하다.
여기까지 OWIN에 대해 살펴봤다. 아직 C#는 초보라서 깊이있게 글을 쓰지 못하는게 아쉽다. 하지만 앞으로의 발전이 더 기대되고 꾸준히 Follow-up 할 닷넷 프로젝트가 될 것 같다.
예제 코드
예제는 모두 Xamarin Studio로 작성했고 GitHub 리포지터리에서 내려받을 수 있다.